Типы перформанс тестов
Каждый тип теста отвечает на свой вопрос: где предел, что будет под пиком, и выдержит ли система сутки без падений. Рассказываю с примерами и графиками, как я подхожу к тестам.
📈
Введение
💡 Понимание различий между типами тестов — это не теория, а ключ к точной интерпретации результатов.
Однажды на проекте в банке команда перепутала тип теста. Запланировали load-тест, чтобы подтвердить стабильность, но сценарий по ошибке был построен как stress — нагрузка поднималась слишком быстро и выше ожидаемого уровня.
В результате система упала через 10 минут, и заказчик решил, что приложение не выдерживает базовую нагрузку. Лишь после анализа стало ясно: проблема была не в перформансе, а в неправильно выбранной методике.
Каждый тип нагрузочного теста отвечает на свой вопрос о системе:
- 🔥 Smoke — всё ли вообще работает?
- 🚀 Capacity — где предел производительности, после которого начинается деградация?
- 📊 Baseline / Load — как система ведёт себя в стабильных условиях и как меняются показатели после изменений?
- 🕒 Soak / Endurance — что будет, если система работает без перерыва несколько часов или дней?
- 💥 Stress / Spike — как система реагирует на пиковые и экстремальные условия?
- 📈 Scalability — растёт ли производительность вместе с добавлением ресурсов?
- 📦 Volume — как влияет объём данных?
- 💻 Client-Side — насколько быстро и плавно работает интерфейс для пользователя?
🧠 Эта статья основана на разговоре и совместных размышлениях с Иваном Зарубиным, инженером по нагрузочному тестированию с 12+ годами опыта.
Мы обсудили, какие бывают типы тестов, зачем каждый нужен и как их правильно применять на проектах.
🔥 Smoke Test — базовая проверка энва
Smoke-тест — это первая и самая простая проверка. Его цель — убедиться, что всё вообще работает: приложение открывается, логин проходит, сценарии выполняются, а мониторинг показывает ожидаемые метрики.
Это своего рода диагностика перед стартом. Smoke не измеряет перформанс. Он лишь подтверждает, что среда, данные и конфигурация готовы к настоящим тестам.
Если smoke падает, то запускать capacity, load или soak просто нет смысла — всё остальное будет давать ложные результаты.
💡 Smoke нужен не для цифр, а чтобы убедиться, что система вообще готова отвечать.
🚀 Capacity Test — где реальный предел системы
Цель capacity-теста — найти верхнюю границу возможностей системы. Мы постепенно повышаем нагрузку: 10%, 20%, 30%… пока не замечаем, что время отклика растёт быстрее обычного, а ошибки начинают появляться чаще.
В этот момент система достигает capacity point — точки, где она уже работает на пределе и дальше становится только хуже.
Capacity-тест показывает, сколько запаса остаётся в текущей конфигурации, и где начинаются реальные ограничения. Это важно не только технически, но и с бизнес-стороны: зная пределы системы, можно заранее спланировать масштабирование, понять, как она поведёт себя при росте трафика и не переплачивать за лишние ресурсы.
💡 Capacity — это тест, который помогает принять разумные решения до того, как продакшен заставит это сделать.
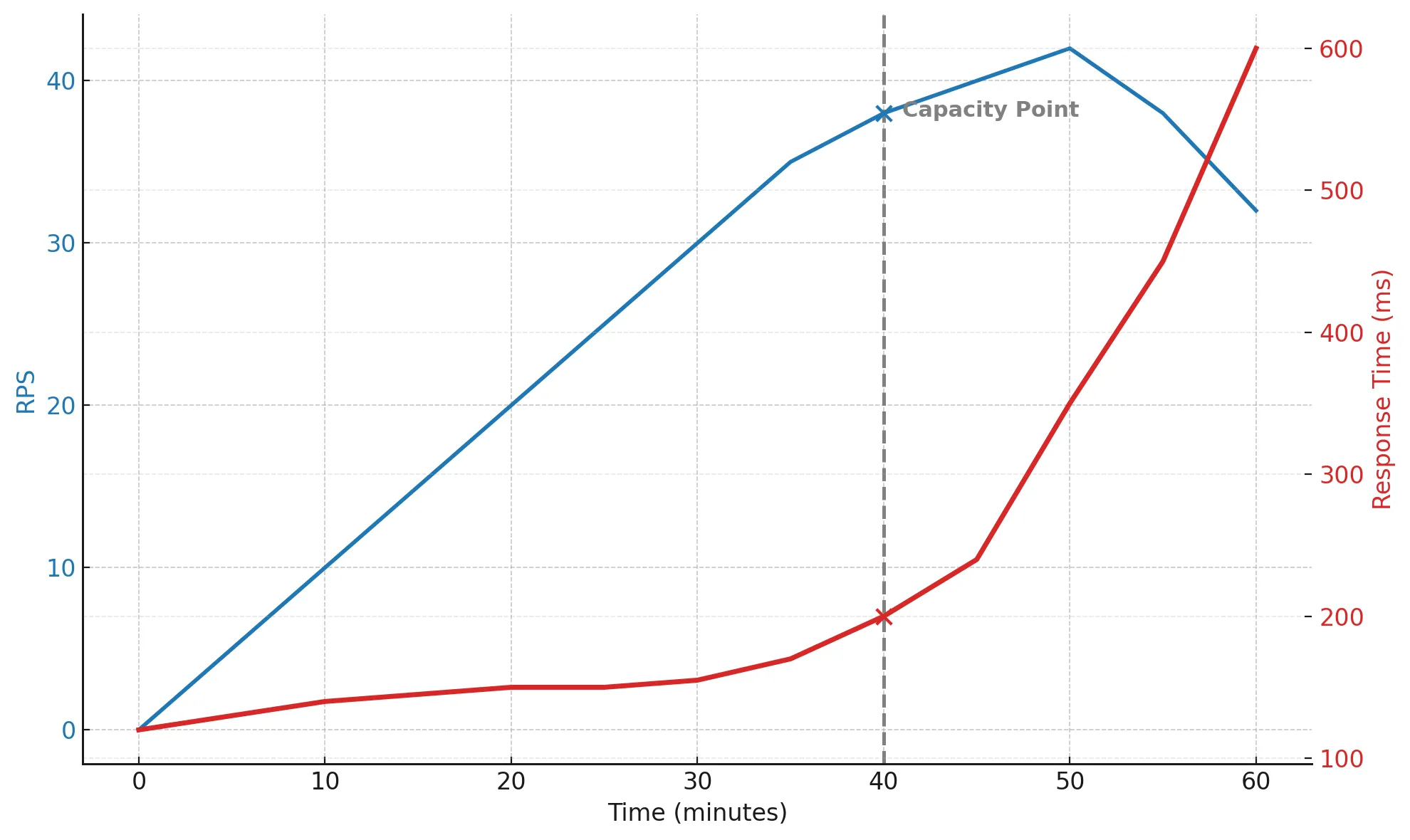
RPS растёт и достигает примерно 40 — это и есть предел пропускной способности. После этого реальный RPS перестаёт увеличиваться, а response time начинает резко расти.
Запросы встают в очередь, CPU приближается к 100%, GC срабатывает всё чаще, и общая производительность начинает деградировать. К 45-й минуте система уже задыхается, а к 60-й время отклика увеличивается в 4 раза.
Такой график идеально показывает момент, где заканчивается масштабирование и начинается борьба за выживание.
📊 Baseline / Load Test — проверяем стабильность системы
Baseline и Load — это, по сути, один и тот же сценарий, но с разными задачами. Сначала выполняется baseline, чтобы понять, как система ведёт себя в спокойном состоянии: время отклика, стабильность, ошибки, использование ресурсов. Это и есть точка отсчёта, с которой потом удобно сравнивать результаты после изменений.
Дальше этот же сценарий используется как load-тест — уже после оптимизаций, релизов или апдейтов, чтобы проверить, стало ли лучше или, по крайней мере, не хуже.
Обычно нагрузку держат на уровне 70–85% от capacity, и система работает под ней 1–2 часа. Если за это время метрики остаются стабильными, без всплесков, утечек или деградаций, значит, система уверенно выдерживает боевую нагрузку.
💡 Baseline помогает зафиксировать норму, а Load — убедиться, что после изменений эта норма не нарушилась.
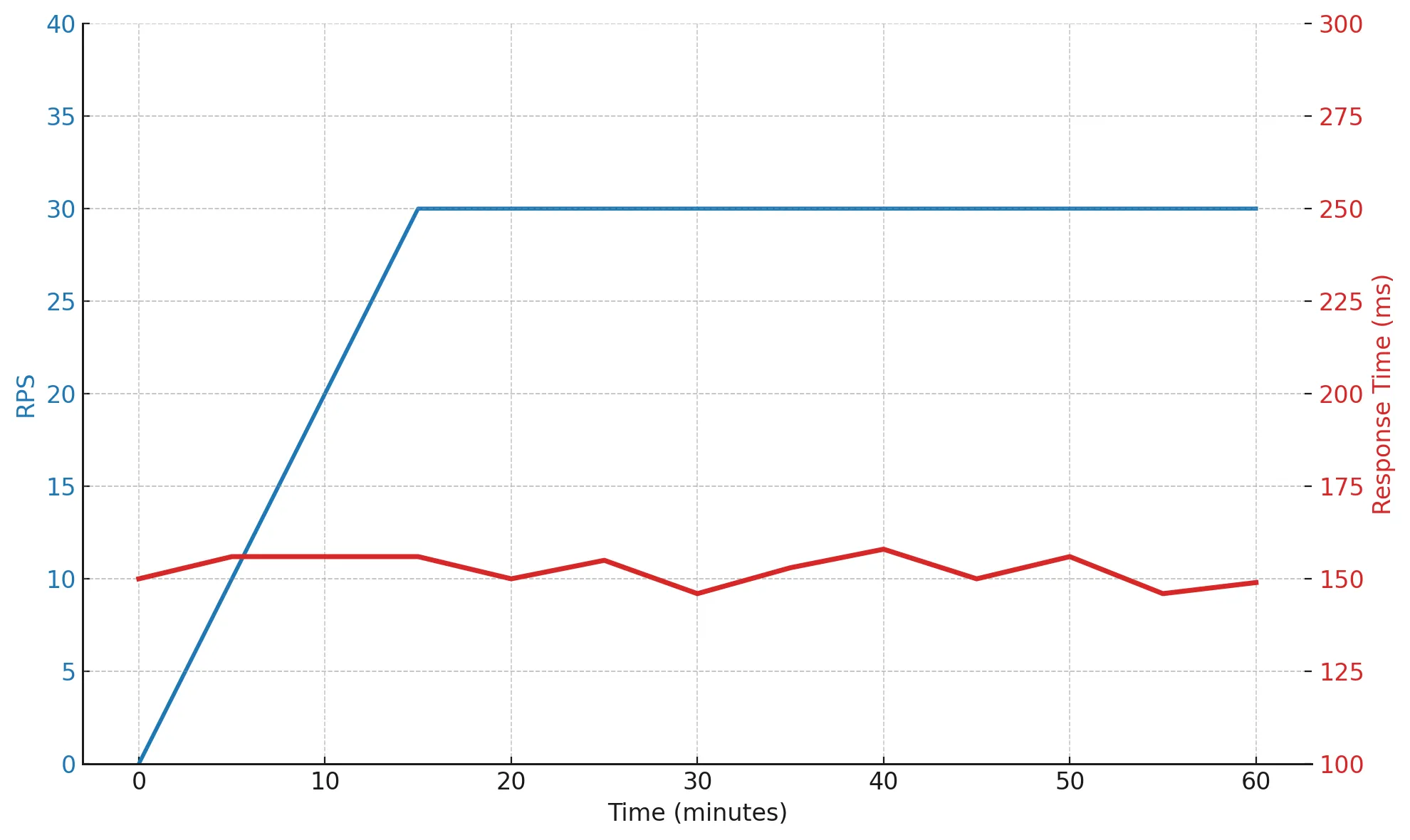
Во время теста нагрузка остаётся постоянной — около 30 RPS (75% от капасити), а response time держится в пределах 150–160 мс. Это означает, что система работает спокойно, предсказуемо и без деградации. Такое поведение говорит о здоровой архитектуре и хорошем запасе по ресурсам.
🕒 Soak / Endurance Test — надёжность на длинной дистанции
Soak-тест — это испытание на выносливость. Его цель — понять, как система ведёт себя при длительной стабильной нагрузке: не час, а 6, 12 или даже 24 часа.
Если capacity и load показывают, как система реагирует на рост нагрузки, то soak отвечает на другой вопрос: “Выдержит ли система долгое постоянное давление без деградации?”
Во время такого теста нагрузка остаётся постоянной, но важно не столько количество запросов, сколько поведение метрик со временем. Мы наблюдаем за:
- ростом latency;
- увеличением GC time;
- ростом потребления памяти;
- количеством открытых потоков или соединений.
Если эти показатели медленно, но стабильно растут, значит, в системе накапливаются проблемы, которые со временем приведут к деградации.
💡 Soak-тест помогает поймать те проблемы, которые невозможно увидеть в коротких тестах — медленные утечки, накопительные эффекты и деградацию перформанса со временем.
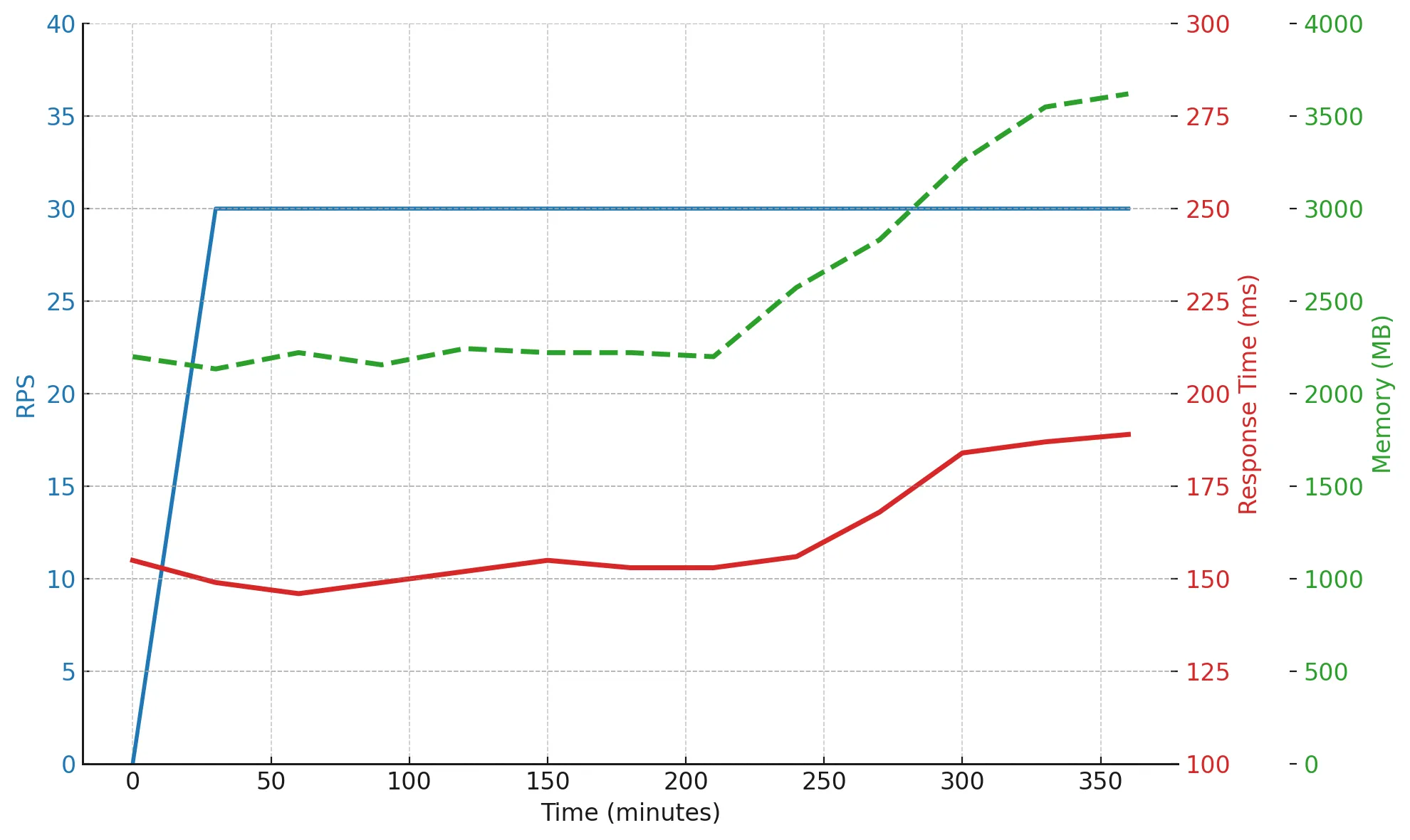
За 6 часов нагрузка оставалась стабильной, но память выросла с 2200 до 3600 МБ — признак возможной утечки или неосвобождаемых ресурсов. При этом response time остаётся в норме: система держится, но устает.
💥 Stress Test — реакция системы на критические условия
Stress-тест — это проверка системы на прочность. Его задача — понять, что произойдёт, когда нагрузка выйдет за пределы нормальной производительности.
Если capacity-тест показывает, где проходит граница, то stress отвечает на вопрос: “Что будет, если эту границу нарушить?”
Такой тест помогает выявить слабые места инфраструктуры, цепочки зависимостей и сценарии отказов, которые невозможно заметить при обычных нагрузках. Главное не просто увидеть момент деградации, а понять как система восстанавливается после перегрузки.
🚨 Когда и зачем проводить стресс-тест:
- перед пиковыми сезонами (например, распродажи или Black Friday);
- перед крупными релизами или маркетинговыми кампаниями;
- при изменении инфраструктуры или автоскейлинга;
- если нужно проверить устойчивость и скорость восстановления после отказа.
Stress моделирует экстремальные условия: взрывной рост числа пользователей, медленные интеграции, частичные сбои сервисов. Он показывает, падает ли система полностью, деградирует частично или умеет восстанавливаться без ручного вмешательства.
💡 Stress-тест показывает, как система ведёт себя на изломе — что ломается первым и как быстро всё восстанавливается после перегрузки.
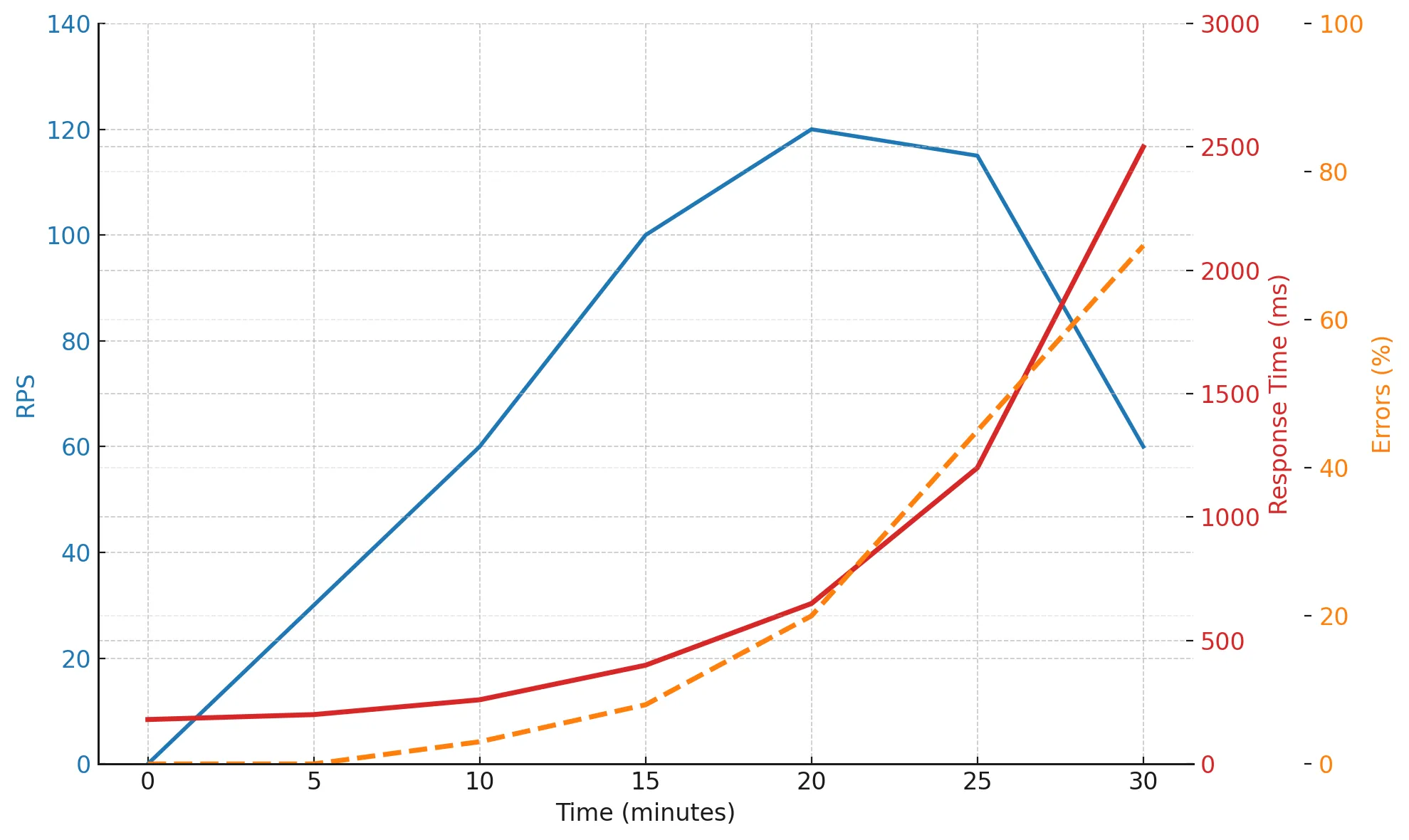
До 20-й минуты система стабильно держит нагрузку, но после выхода за предел пропускной способности RPS перестаёт расти — наступает плато. Зато response time растёт экспоненциально, а ошибки начинают множиться.
К 25–30-й минуте система уже почти не отвечает корректно — чёткий сигнал о границах устойчивости.
⚠️ Важно: на большинстве проектов stress и spike тесты проводят нечасто. Чаще ограничиваются capacity и soak, которые дают достаточно информации для анализа и планирования.
⚡️ Spike Test — устойчивость к кратковременным пикам
Spike-тест проверяет, как система реагирует на внезапные и кратковременные всплески нагрузки. Представь: выходит реклама, push-рассылка или начинается акция — и за считанные секунды на сервис заходят тысячи пользователей.
Главный вопрос здесь не “где предел”, а как быстро система адаптируется и возвращается в норму. Успевает ли она освободить ресурсы? Не зависают ли соединения? Не накапливаются ли ошибки в очередях?
⚖️ Чем отличается от стресс-теста:
Spike не доводит систему до отказа — он мягче, и проверяет эластичность и скорость реакции. Часто такие тесты идут в паре со стрессом, чтобы увидеть, насколько гибко система справляется с короткими, но резкими изменениями трафика.
Spike помогает выявить узкие места, которые незаметны под стабильной нагрузкой:
- медленные кеши,
- неэффективный автоскейлинг,
- пул потоков, который не успевает расширяться вовремя.
💡 Spike-тест — отличный способ убедиться, что система выдержит внезапный всплеск трафика и спокойно вернётся в рабочее состояние.
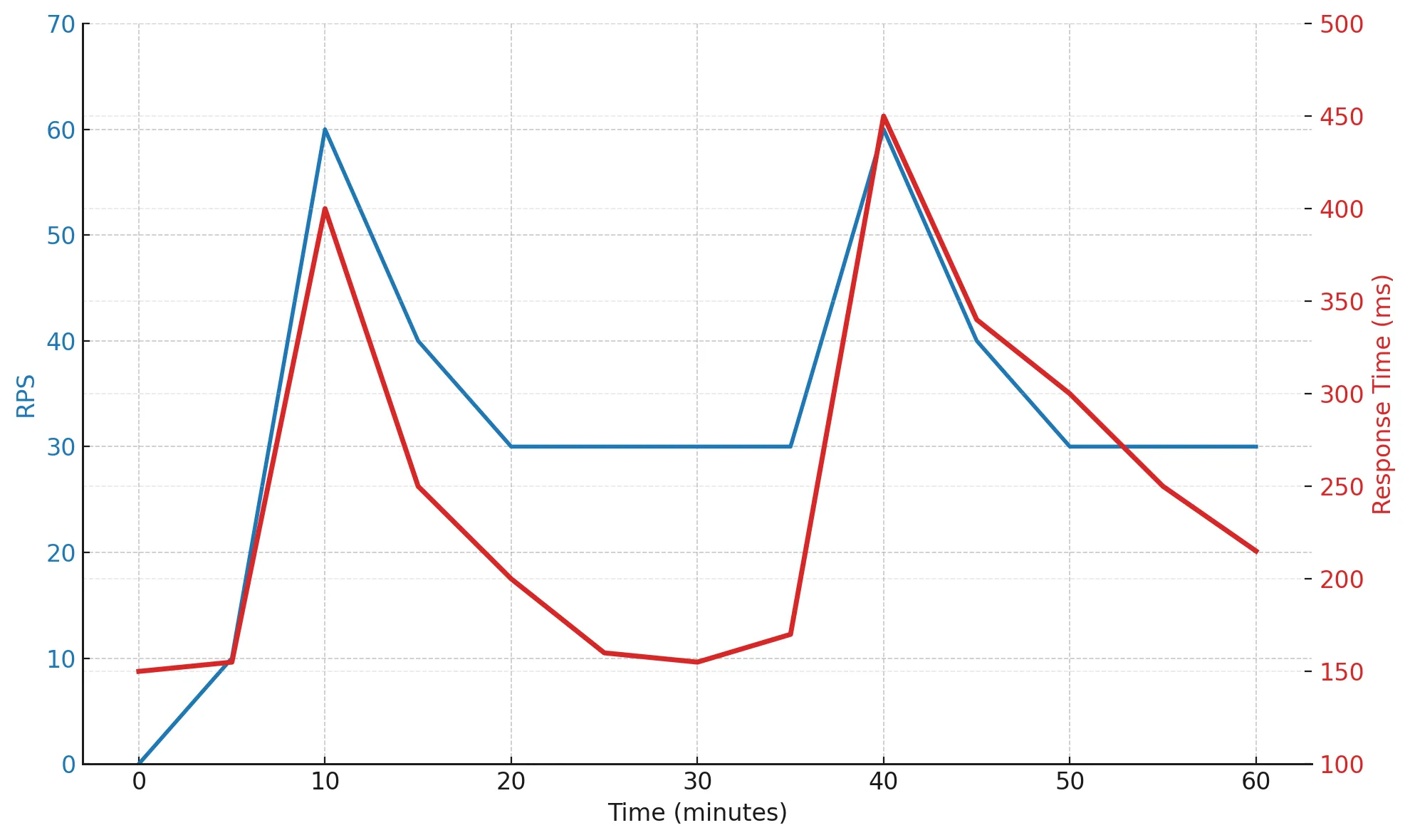
На 10-й и 40-й минутах видно резкие всплески нагрузки — RPS подскакивает, response time увеличивается до 400–450 мс, но после спада система быстро восстанавливается.
Такой результат показывает, что система обладает хорошим запасом гибкости. Она способна выдерживать резкие пики без деградации и утечек.
📈 Scalability Test — масштабируемость
Scalability-тест проверяет, насколько эффективно система использует добавленные ресурсы. Если мы увеличим количество серверов, подов или CPU, вырастет ли производительность пропорционально, или всё упрётся в архитектурные ограничения?
В микросервисных системах это особенно важно: разные сервисы часто зависят друг от друга, и один ботлнек может обнулить весь эффект от масштабирования. Такой тест помогает увидеть, где система перестаёт расти линейно и насколько она готова к горизонтальному масштабированию.
🚗 Представь, что ты ставишь второй двигатель в машину, но он крутит те же колёса, быстрее она не поедет. То же и здесь: добавление ресурсов не всегда приводит к ускорению, если архитектура ограничена узкими местами. Scalability-тест помогает эти ограничения найти и измерить.
💡 Scalability-тест показывает, насколько эффективно работает масштабирование и где стоит доработать архитектуру, чтобы ресурсы приносили максимальную отдачу.
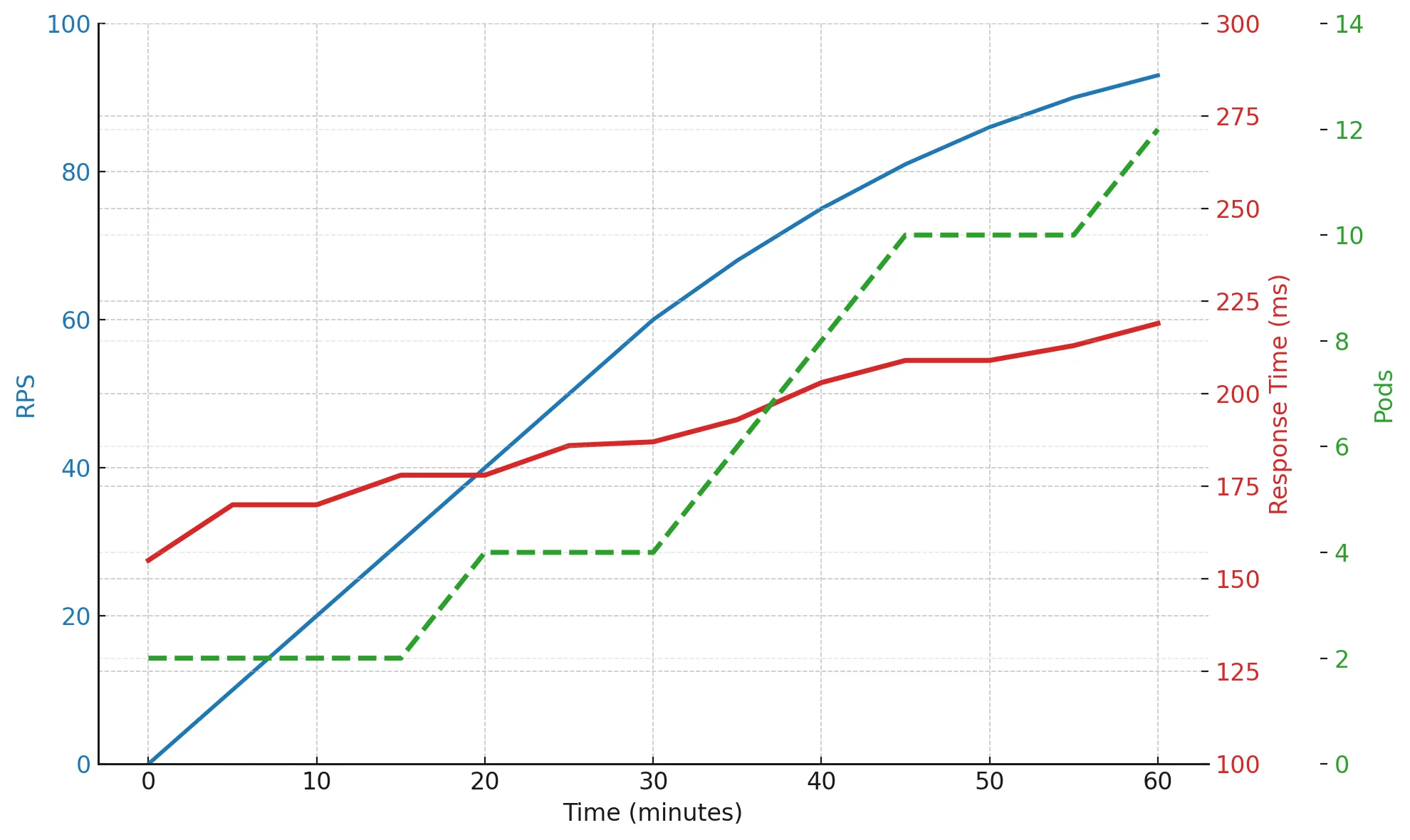
С увеличением числа подов с 2 до 12 — RPS вырос почти в 5 раз, но response time тоже слегка увеличился. Это нормальная картина: система масштабируется, но не идеально — часть производительности теряется на синхронных зависимостях, сетевых задержках или ограничениях на уровне базы данных.
📦 Volume Test — влияние объёма данных
Volume-тест проверяет, как система ведёт себя при росте объёма данных. Это своего рода тест на зрелость архитектуры: если база увеличивается в несколько раз, а производительность падает незначительно, значит, система спроектирована с запасом и умеет масштабироваться по данным.
Такой тест помогает понять, насколько архитектура устойчива к накоплению информации без изменений кода. В реальном мире база, которая сегодня весит 100 ГБ, через год может достичь терабайта,
и важно заранее знать, как это скажется на времени отклика и нагрузке на хранилище.
Volume-тест отвечает на вопрос: “Производительность деградирует постепенно или резко обваливается при определённом объёме данных?”
💾 Когда особенно полезен:
- при миграциях и репликации данных;
- при переходе на новую базу или изменение схемы хранения;
- при оценке времени выполнения массовых операций записи и чтения.
Он показывает, насколько быстро и корректно система работает с большими объёмами информации, и помогает заранее спрогнозировать, где появятся проблемы.
💡 Volume-тест показывает, как стареет система вместе с базой и в какой момент стоит пересматривать запросы, индексы или архитектуру хранения данных.
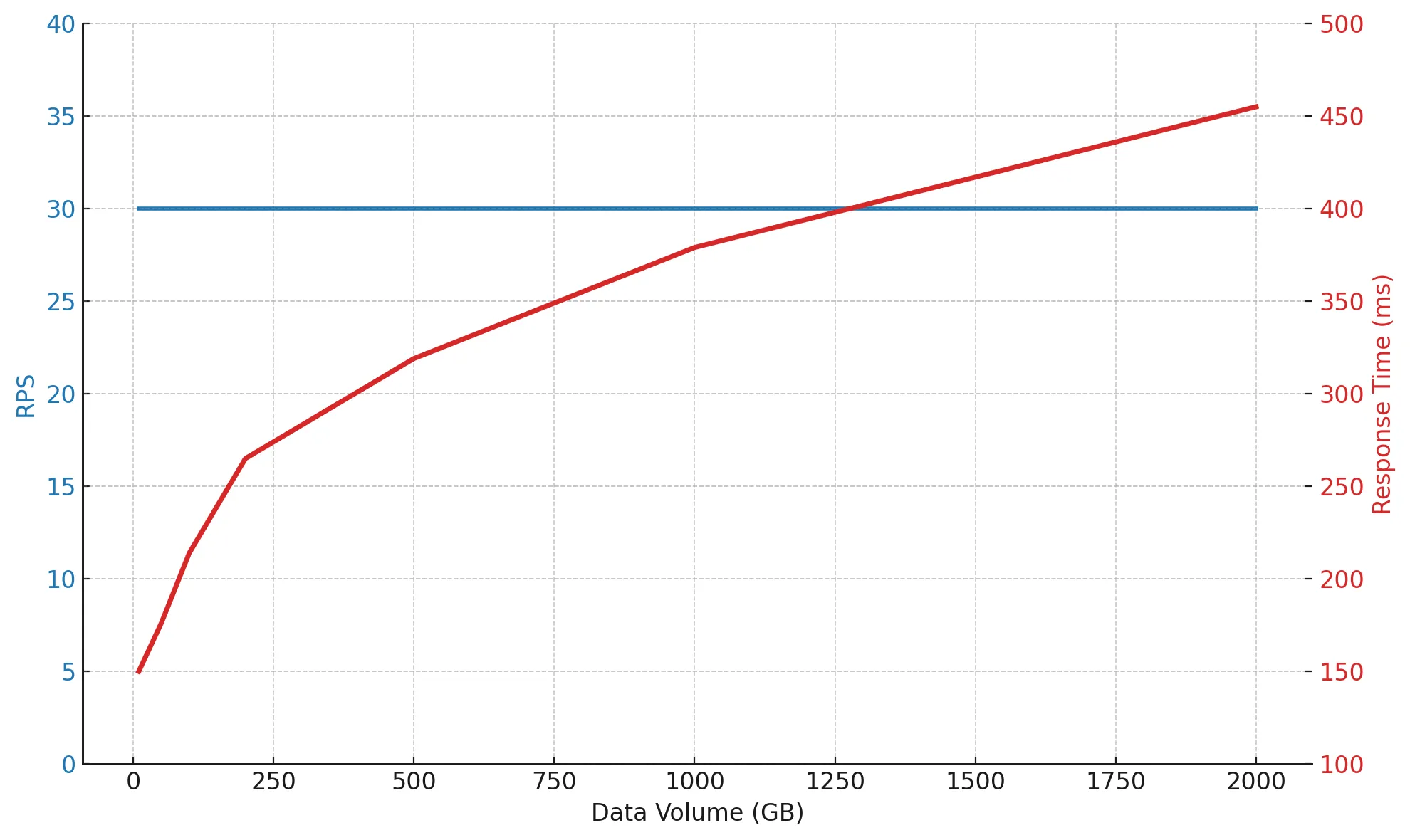
При увеличении объёма данных с 10 до 2000 ГБ нагрузка остаётся прежней — 30 RPS, но response time постепенно растёт с 150 до 433 мс.
Это ожидаемо: чем больше данных, тем дольше поиск, фильтрация и индексирование.
💻 Client-Side — не забываем про фронт
Когда мы говорим о перф тестировании, чаще всего думаем про бэк: API, базы, микросервисы. Но есть и другая сторона истории — фронт, то, что видит и ощущает пользователь.
Client-side тесты проверяют, насколько быстро и плавно работает интерфейс: загружается ли страница, реагируют ли кнопки, не прыгает ли верстка при рендере. Это тест не про сервера, а про восприятие скорости.
Даже если бэкенд справляется идеально, медленный JavaScript, тяжёлые изображения или неудачный рендер могут сделать интерфейс тормозным. Поэтому такие тесты стоит запускать параллельно с backend-side, чтобы видеть полную картину — от API до визуального отклика. Иногда сервер возвращает ответ за 200 мс, но пользователь видит задумчивость из-за лишней логики на фронте.
🎯 Что измеряют client-side тесты:
- LCP (Largest Contentful Paint) — скорость отображения основного контента;
- INP (Interaction to Next Paint) — отзывчивость интерфейса;
- CLS (Cumulative Layout Shift) — стабильность рендеринга;
- общие показатели загрузки и рендеринга страниц.
💡 Перформанс — это не только RPS и latency, это ещё и то, как быстро всё выглядит и ощущается для пользователя. Если интерфейс тормозит, пользователи просто уходят.
Подробно об этом типе тестов напишу в отдельной статье, где разберём примеры метрик, инструменты (Lighthouse, Playwright, DevTools) и подходы к тестированию UI под нагрузкой.
🌀 Цикл тестирования — что за чем
Этот цикл — не жёсткий шаблон, а гибкая стратегия, которую можно подстроить под конкретную систему. Для веб-приложений приоритетом может быть скорость пользовательских сценариев, а для интеграционных шин* — стабильность обмена сообщениями и поведение при сбоях.
Главное — не просто пройти все этапы, а понимать, зачем ты проводишь каждый тест и какой ответ хочешь получить.
🔁 Пример базовой последовательности
- 🔥 Smoke — проверяем, что окружение готово и всё запускается.
- 🚀 Capacity — ищем предел, где система перестаёт масштабироваться.
- 📊 Baseline / Load — фиксируем норму и проверяем стабильность под реальной нагрузкой.
- 🕒 Soak — наблюдаем, как система ведёт себя во времени и не деградирует ли она.
- 💥 Stress / ⚡ Spike — проверяем, как система реагирует на экстремальные и пиковые условия.
- 📈 Scalability / 📦 Volume — оцениваем, растёт ли производительность с ресурсами и объёмом данных.
- 💻 Client-Side — убеждаемся, что фронт не тормозит, даже когда всё остальное под нагрузкой.
Эта последовательность даёт цельную картину поведения системы — от первых запросов до критических ситуаций. Это не просто набор тестов, а единый процесс, который помогает понять, как система живёт, дышит и реагирует на изменения.
🧩 Тесты ради понимания, не ради формальности
Когда тесты запускают ради отчёта, результат быстро превращается в бюрократию. На одном проекте инженеры честно провели все тесты — графики ровные, цифры зелёные, всё выглядело идеально. А через месяц после релиза система упала под реальной нагрузкой, потому что никто не заметил узкое место в базе.
На другом проекте команда подошла осмысленно. Stress-тест вовремя показал, что тайм-ауты настроены неправильно, и релиз буквально спасли за два дня до выхода. Этот контраст отлично показывает: тестирование ради галочки — бессмысленно.
🎯 Тест — это инструмент, а не цель
Тип теста не должен быть самоцелью. Главное — не прогнать сценарий, а понять, как живёт система, где у неё слабые места и какие риски могут выстрелить на проде.
Перед запуском любого теста стоит спросить себя:
Что я хочу этим тестом узнать?
Иногда достаточно короткого Load, чтобы убедиться, что всё стабильно. А иногда без Stress и Soak релиз выпускать просто опасно.
Главное, чтобы каждый тест имел смысл и приносил пользу, не только техническую, но и бизнесовую.
⚖️ Рациональность важнее количества
В перформанс-тестировании главный навык — рациональность. Это не про число отчётов и красивые графики, а про умение выбрать минимальный набор тестов, который даст максимум понимания.
Иногда важнее вовремя остановиться и правильно интерпретировать результаты, чем ещё раз прогнать ради уверенности.
🤝 Культура прозрачности и доверия
Хорошее тестирование создаёт культуру прозрачности. Все участники команды понимают реальные границы системы, а не живут догадками.
Это укрепляет доверие между инженерами, девопсами и бизнесом, делает решения осознанными и снижает риск неприятных сюрпризов на проде.
🩺 Диагностика, не бюрократия
Нагрузочное тестирование похоже на медицинскую диагностику: задача — не просто измерить давление, а понять, почему оно изменилось и что с этим делать.
Тесты — это наши анализы, которые показывают состояние системы. Если интерпретировать их правильно, можно предотвратить инфаркт прода и продлить жизнь продукта.
Перформанс-инженер — не просто человек, который гоняет тесты.
Это специалист, который помогает команде и бизнесу принимать решения на основе данных, прогнозировать поведение системы и строить более устойчивую архитектуру.