Утечка потоков в Java: поиск проблемы и фикс
Как я столкнулся с утечкой памяти, не связанной с heap или GC.
🧵
Введение
Проект — крупный клиент из e-commerce и healthcare в США (сори, NDA, название не покажу).
От стабильности этого модуля зависела важная часть бизнес-процессов, поэтому тест имел весомую цель — убедиться, что система выдерживает длительную и высокую нагрузку без деградации.
На практике всё пошло немного интереснее. Во время прогона на перф-окружении сервис, работающий в Kubernetes, стал периодически падать с ошибкой:
fatal Java Runtime Environment error
Kubernetes перезапускал его, но спустя некоторое время история повторялась.
Сначала это выглядело как классическая утечка памяти, но heap оказался чистым. Проблема пряталась глубже — в нативной памяти и потоках.
Содержание
- Контекст и условия теста
- Анализ и первые гипотезы
- Поиск причины
- Исправление и выбор решения
- Повторная проверка
- Что мы вынесли из этого
Контекст и условия теста
| Параметр | Значение |
|---|---|
| Платформа: | Kubernetes |
| Язык: | Java 17 |
| Сервис: | компонент расчёта цен (🔒 название скрыто) |
| Тип теста: | Capacity |
| Цель: | постепенно увеличивать нагрузку и найти capacity point — момент, когда система достигает пика производительности перед деградацией |
Анализ и первые гипотезы
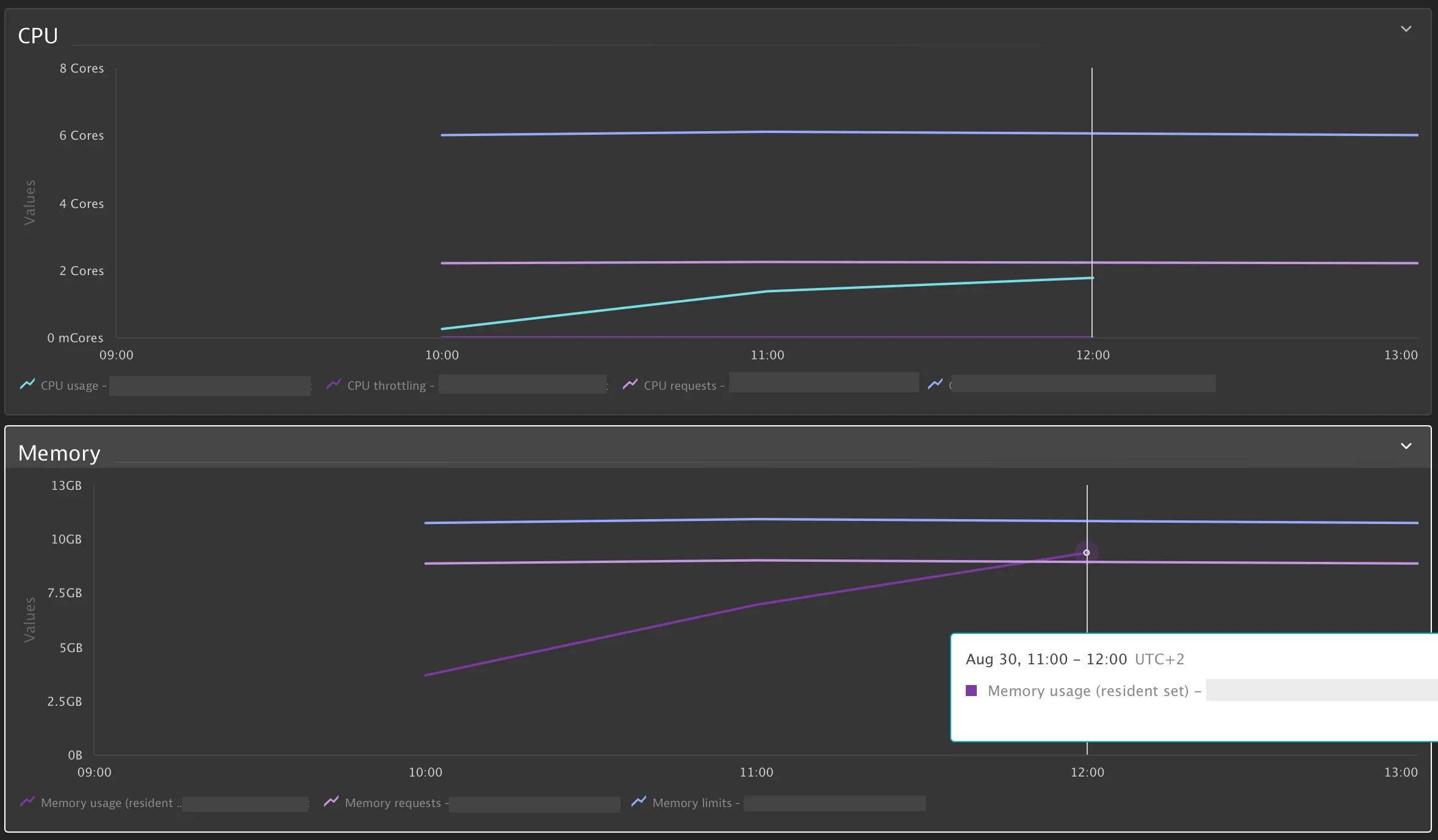
CPU увеличивался, но линейно и несильно, а вот память уверенно росла вверх к лимитам каждый раз.
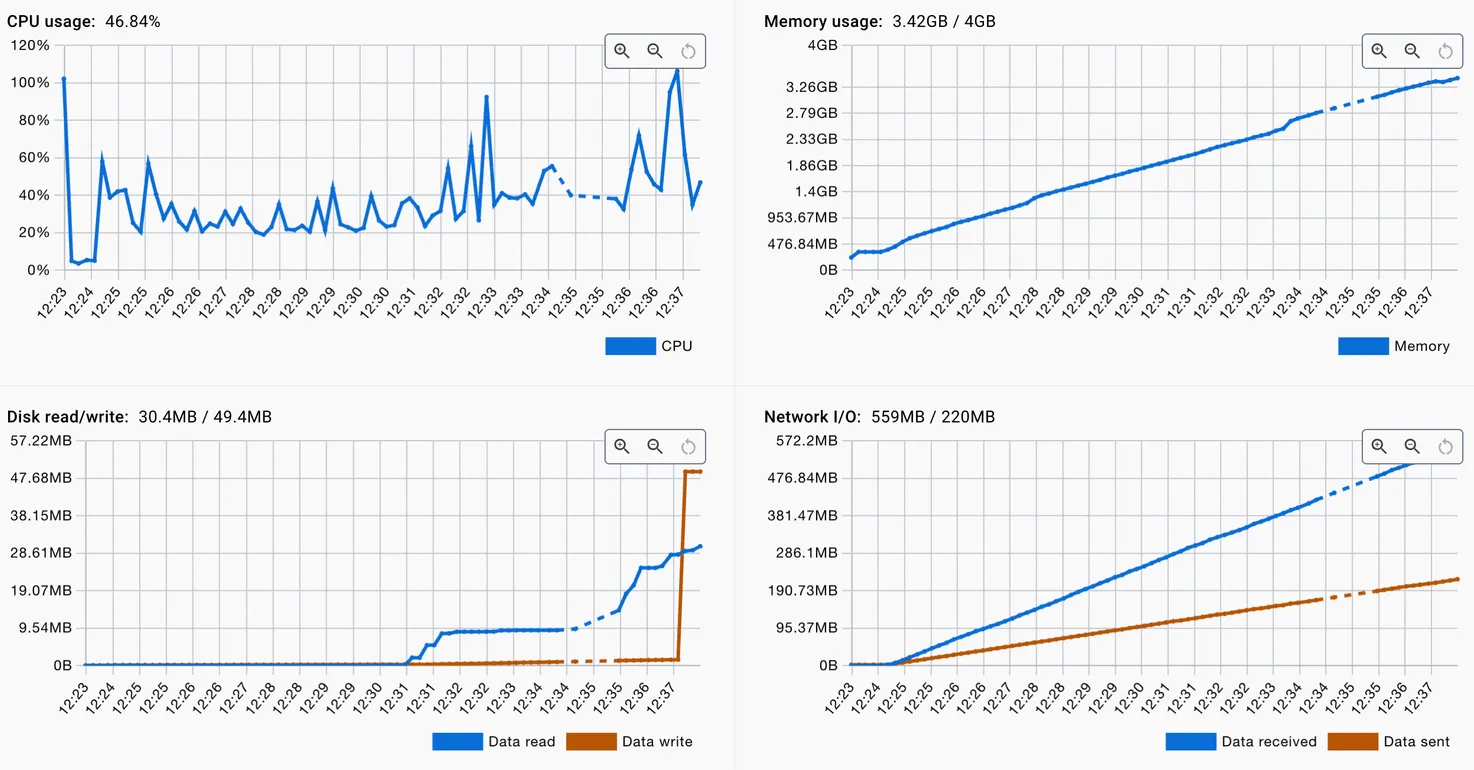
Чтобы исключить влияние внешних факторов, я запустил сервис локально в Docker Desktop и прогнал тот же тест.
Результат повторился: память растёт линейно, CPU — стабильно. То есть сервис не перегружен вычислениями, но память утекает.
Ага, дело не в инфраструктуре, а в нативной памяти. Логи JVM это подтвердили:
A fatal error has been detected by the Java Runtime Environment:
Native memory allocation (mprotect) failed to map memory for guard stack pages
Attempt to protect stack guard pages failed
os::commit_memory(...): error='Not enough space' (errno=12)
Проще говоря:
Потоков стало слишком много, и в оперативной памяти не осталось места для размещения стеков новых потоков.
Поиск причины
Просмотр кода быстро вывел на подозрительный участок: внутри метода enrich() создавался новый ExecutorService при каждом вызове.
Всё выглядело аккуратно — CompletableFuture, асинхронные вызовы, знакомая схема. Но пул потоков нигде не закрывался.
❌ До фикса
ExecutorService executor = Executors.newFixedThreadPool(WORKERS);
CompletableFuture<Void> prices = CompletableFuture.runAsync(
() -> enrichPrices(context, productIds), executor);
CompletableFuture<Void> products = CompletableFuture.runAsync(
() -> enrichProducts(context, productIds), executor);
joinAndRethrow(prices, products);
Каждый запрос создавал новый пул потоков. Потоки оставались живыми и постепенно заполняли память, пока JVM не достигала лимита.
Исправление и выбор решения
❌ Первое решение (неверное)
Первоначальный фикс казался логичным: добавить try/finally и закрывать пул после каждого использования.
ExecutorService executor = Executors.newFixedThreadPool(WORKERS);
try {
CompletableFuture<Void> prices = CompletableFuture.runAsync(
() -> enrichPrices(context, productIds), executor);
CompletableFuture<Void> products = CompletableFuture.runAsync(
() -> enrichProducts(context, productIds), executor);
joinAndRethrow(prices, products);
} finally {
executor.shutdown();
}
Проблема: Это хоть и устранило утечку памяти, но подход был в корне неправильным. На каждый запрос мы создавали пул из N потоков и тут же его уничтожали. Создание и уничтожение потоков — дорогостоящая операция, которая:
- Создаёт излишнюю нагрузку на систему
- Снижает производительность при высокой нагрузке
- Противоречит самой идее пула потоков (переиспользование ресурсов)
✅ Оптимальное решение
Правильный подход — создать пул потоков один раз при старте приложения и переиспользовать его для всех запросов.
Инициализация пула (например, в конфигурации Spring или при старте компонента):
@Configuration
public class ExecutorConfig {
@Bean(destroyMethod = "shutdown")
public ExecutorService enrichmentExecutor() {
return Executors.newFixedThreadPool(WORKERS);
}
}
Использование в методе:
private final ExecutorService executor; // внедряем через конструктор
public void enrich(Context context, List<String> productIds) {
CompletableFuture<Void> prices = CompletableFuture.runAsync(
() -> enrichPrices(context, productIds), executor);
CompletableFuture<Void> products = CompletableFuture.runAsync(
() -> enrichProducts(context, productIds), executor);
joinAndRethrow(prices, products);
}
Почему это лучше:
- Эффективность: потоки создаются один раз, а не на каждый запрос
- Производительность: нет накладных расходов на создание/уничтожение потоков
- Контроль: легко управлять количеством потоков и их жизненным циклом
- Graceful shutdown: Spring (или другой контейнер) корректно закроет пул при остановке приложения
После рефакторинга система стала не только стабильной, но и эффективной — каждый запрос использует уже готовые потоки из пула.
Повторная проверка
Повторный тест подтвердил результат:
✅ память вышла на стабильный уровень;
✅ число потоков перестало увеличиваться;
✅ ошибок JVM больше не наблюдалось.
Сервис стал предсказуем и устойчив даже при длительной нагрузке.
Что мы вынесли из этого
Эта история — отличный пример того, что не всякий фикс — правильный фикс. Один не закрытый ExecutorService создал утечку памяти, но правильным решением было не просто “починить утечку”, а переосмыслить архитектуру управления потоками.
⚠️ Важный урок:
Закрывать ExecutorService после каждого использования — это антипаттерн. Пулы потоков существуют именно для переиспользования, а не для одноразового применения.
💡 Что стоит помнить:
- Ошибки JVM, связанные с native memory, часто указывают на утечки потоков, а не heap.
- Создание пула потоков на каждый запрос — это архитектурная ошибка, даже если вы корректно его закрываете.
- Правильный подход: создать пул один раз при старте приложения и переиспользовать его на протяжении всего жизненного цикла.
- Capacity-тесты и длительные прогоны помогают выявить не только утечки, но и фундаментальные проблемы в архитектуре.